LDA
LDA 原理
给定数据\(\mathbf{X}\in \mathbb{R}^{N\times p}\),以及\(\mathbf{y}\in \{0,1\}\),构成输入与输出训练数据对\(D=\{(\mathbf{x}_1,\mathbf{y}_1),...,(\mathbf{x}_N,\mathbf{y}_N)\}\)。训练集\(D\)表示整个训练数据集有\(N\)条数据,每一条数据的维度为\(p\)维,所有数据只有两个类别分别对应于输出\(\mathbf{y}\)取值为0或者1。
首先假设两类数据中第一类数据\(\mathbf{x}_{c1}\)有\(|\mathbf{x}_{c1}|=N_1\)个,第二类数据有\(|\mathbf{x}_{c2}|=N_2\)个,且\(N_1+N_2=N\)。两类数据的均值和方差可以表示为:
\[ \bar{\mathbf{x_1}}=\frac{1}{N_1}\sum_{i=1}^{N_1}\mathbf{x}_i \]
\[ \bar{\mathbf{x_2}}=\frac{1}{N_2}\sum_{i=1}^{N_2}\mathbf{x}_i \]
\[ \mathbf{S}_{x1}=\frac{1}{N_1}\sum_{i=1}^{N_1}(\mathbf{x}_i-\bar{\mathbf{x_1}})(\mathbf{x}_i-\bar{\mathbf{x_1}})^T \]
\[ \mathbf{S}_{x2}=\frac{1}{N_2}\sum_{i=1}^{N_2}(\mathbf{x}_i-\bar{\mathbf{x_2}})(\mathbf{x}_i-\bar{\mathbf{x_2}})^T \]
对输入的\(p\)维特征进行降维有\(\mathbf{z}_i=\mathbf{W}^T\mathbf{x}_i\),其中\(\mathbf{z}\)表示降维之后的数据,那么降维之后的数据的均值和方差分别为:
\[ \bar{\mathbf{z_1}}=\frac{1}{N_1}\sum_{i=1}^{N_1}\mathbf{W}^T\mathbf{x}_i \]
\[ \mathbf{S}_1=\frac{1}{N_1}\sum_{i=1}^{N_1}(\mathbf{W}^T\mathbf{x}_i-\bar{\mathbf{z_1}})(\mathbf{W}^T\mathbf{x}_i-\bar{\mathbf{z_1}})^T \]
\[ \bar{\mathbf{z_2}}=\frac{1}{N_2}\sum_{i=1}^{N_2}\mathbf{W}^T\mathbf{x}_i \]
\[ \mathbf{S}_2=\frac{1}{N_2}\sum_{i=1}^{N_2}(\mathbf{W}^T\mathbf{x}_i-\bar{\mathbf{z_2}})(\mathbf{W}^T\mathbf{x}_i-\bar{\mathbf{z_2}})^T \]
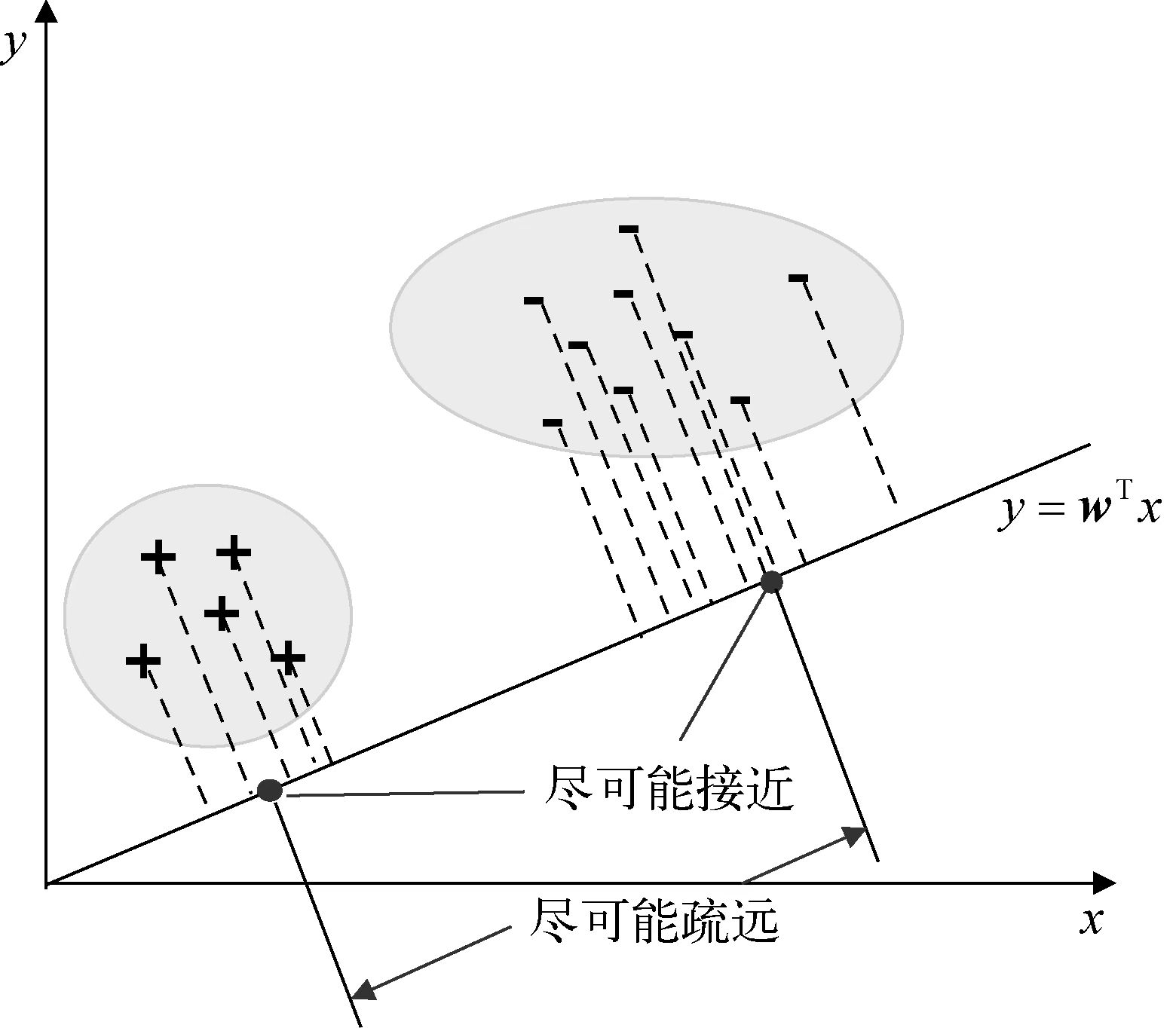 LDA的示意图如上图所示,它的最终目的是使得同一类型的数据之间尽可能地聚集在一起,使得位于不同类别的两类数据尽可能分开。首先是让位于同一类别的数据尽可能地聚集在一起,实际上就是让两类数据的方差尽可能小\(\min
\mathbf{S}_1+\mathbf{S}_2\)。其次是让位于不同类别的数据之间尽可能离得远,这一点可以通过让两类数据的中心也就是均值之间的距离尽可能远\(\max||
\bar{\mathbf{z}_1}-\bar{\mathbf{z}_2}||_F^2\)
最终LDA的目标函数可以表示为:
LDA的示意图如上图所示,它的最终目的是使得同一类型的数据之间尽可能地聚集在一起,使得位于不同类别的两类数据尽可能分开。首先是让位于同一类别的数据尽可能地聚集在一起,实际上就是让两类数据的方差尽可能小\(\min
\mathbf{S}_1+\mathbf{S}_2\)。其次是让位于不同类别的数据之间尽可能离得远,这一点可以通过让两类数据的中心也就是均值之间的距离尽可能远\(\max||
\bar{\mathbf{z}_1}-\bar{\mathbf{z}_2}||_F^2\)
最终LDA的目标函数可以表示为:
\[ L = \frac{|| \bar{\mathbf{z}_1}-\bar{\mathbf{z}_2}||_F^2}{\mathbf{S}_1+\mathbf{S}_2} \]
首先对分子进行化简有:
\[ \begin{aligned} || \bar{\mathbf{z}_1}-\bar{\mathbf{z}_2}||_F^2&=||\frac{1}{N_1}\sum_{x=1}^{N_1}\mathbf{W}^T\mathbf{x}_i-\frac{1}{N_2}\sum_{x=1}^{N_2}\mathbf{W}^T\mathbf{x}_i||_F^2\\ &=||\mathbf{W}^T(\frac{1}{N_1}\sum_{t=1}^{N_1}\mathbf{x}_i-\frac{1}{N_2}\sum_{t=1}^{N_2}\mathbf{x}_i)||_F^2\\ &=||\mathbf{W}^T(\bar{\mathbf{x_1}}-\bar{\mathbf{x_2}})||_F^2\\ &=\mathbf{W}^T(\bar{\mathbf{x_1}}-\bar{\mathbf{x_2}})(\bar{\mathbf{x_1}}-\bar{\mathbf{x_2}})^T\mathbf{W} \end{aligned} \]
对分母进行化简有:
\[ \begin{aligned} \mathbf{S_1+S_2}&=\frac{1}{N_1}\sum_{i=1}^{N_1}(\mathbf{W}^T\mathbf{x}_i-\bar{\mathbf{z_1}})(\mathbf{W}^T\mathbf{x}_i-\bar{\mathbf{z_1}})^T+\frac{1}{N_2}\sum_{i=1}^{N_2}(\mathbf{W}^T\mathbf{x}_i-\bar{\mathbf{z_2}})(\mathbf{W}^T\mathbf{x}_i-\bar{\mathbf{z_2}})^T\\ &=\frac{1}{N_1}\sum_{i=1}^{N_1}(\mathbf{W}^T\mathbf{x}_i-\frac{1}{N_1}\sum_{i=1}^{N_1}\mathbf{W}^T\mathbf{x}_i)(\mathbf{W}^T\mathbf{x}_i-\frac{1}{N_1}\sum_{i=1}^{N_1}\mathbf{W}^T\mathbf{x}_i)^T\\ &+\frac{1}{N_2}\sum_{i=1}^{N_2}(\mathbf{W}^T\mathbf{x}_i-\frac{1}{N_2}\sum_{i=1}^{N_2}\mathbf{W}^T\mathbf{x}_i)(\mathbf{W}^T\mathbf{x}_i-\frac{1}{N_2}\sum_{i=1}^{N_2}\mathbf{W}^T\mathbf{x}_i)^T\\ &=\mathbf{W}^T\frac{1}{N_1}\sum_{i=1}^{N_1}(\mathbf{x}_i-\frac{1}{N_1}\sum_{i=1}^{N_1}\mathbf{x}_i)(\mathbf{x}_i-\frac{1}{N_1}\sum_{i=1}^{N_1}\mathbf{x}_i)^T\mathbf{W}\\ &=\mathbf{W}^T\frac{1}{N_2}\sum_{i=1}^{N_2}(\mathbf{x}_i-\frac{1}{N_2}\sum_{i=1}^{N_2}\mathbf{x}_i)(\mathbf{x}_i-\frac{1}{N_2}\sum_{i=1}^{N_2}\mathbf{x}_i)^T\mathbf{W}\\ &=\mathbf{W}^T\frac{1}{N_1}\sum_{i=1}^{N_1}(\mathbf{x}_i-\bar{\mathbf{x}_1})(\mathbf{x}_i-\bar{\mathbf{x}_1})^T\mathbf{W}+\mathbf{W}^T\frac{1}{N_2}\sum_{i=1}^{N_2}(\mathbf{x}_i-\bar{\mathbf{x}_2})(\mathbf{x}_i-\bar{\mathbf{x}_2})^T\mathbf{W}\\ &=\mathbf{W}^T(\mathbf{S}_{x1}-\mathbf{S}_{x2})\mathbf{W} \end{aligned} \]
最终LDA的目标函数可以表示为:
\[ L = \frac{\mathbf{W}^T(\bar{\mathbf{x_1}}-\bar{\mathbf{x_2}})(\bar{\mathbf{x_1}}-\bar{\mathbf{x_2}})^T\mathbf{W}}{\mathbf{W}^T(\mathbf{S}_{x1}-\mathbf{S}_{x2})\mathbf{W}} \]
令\(\mathbf{S}_{w}= (\bar{\mathbf{x_1}}-\bar{\mathbf{x_2}})(\bar{\mathbf{x_1}}-\bar{\mathbf{x_2}})^T\),\(\mathbf{S}_{b}= \mathbf{S}_{x1}-\mathbf{S}_{x2}\)有:
\[ L = \frac{\mathbf{W}^T\mathbf{S}_w\mathbf{W}}{\mathbf{W}^T\mathbf{S}_b\mathbf{W}} \]
求解目标函数中的\(\mathbf{W}\)可以得到最终的解。
算法实现
1 | |