ChatGPT
ChatGPT是由InstructGPT演变而来的, 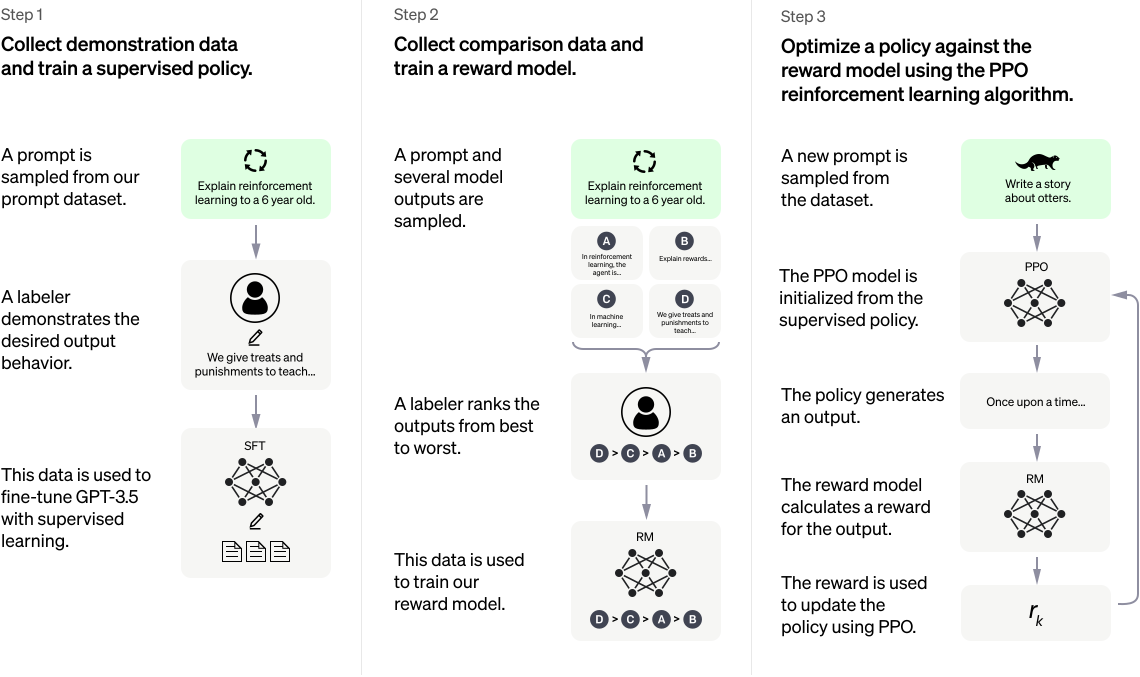
简介
它的训练可以分为四个阶段:
- 基于Mask的自监督训练
- 人工标注的监督QA训练
- 利用人工对答案优先级的标注数据进行监督训练
- 利用学习到的人类喜好通过强化学习训练判别模型
自监督训练
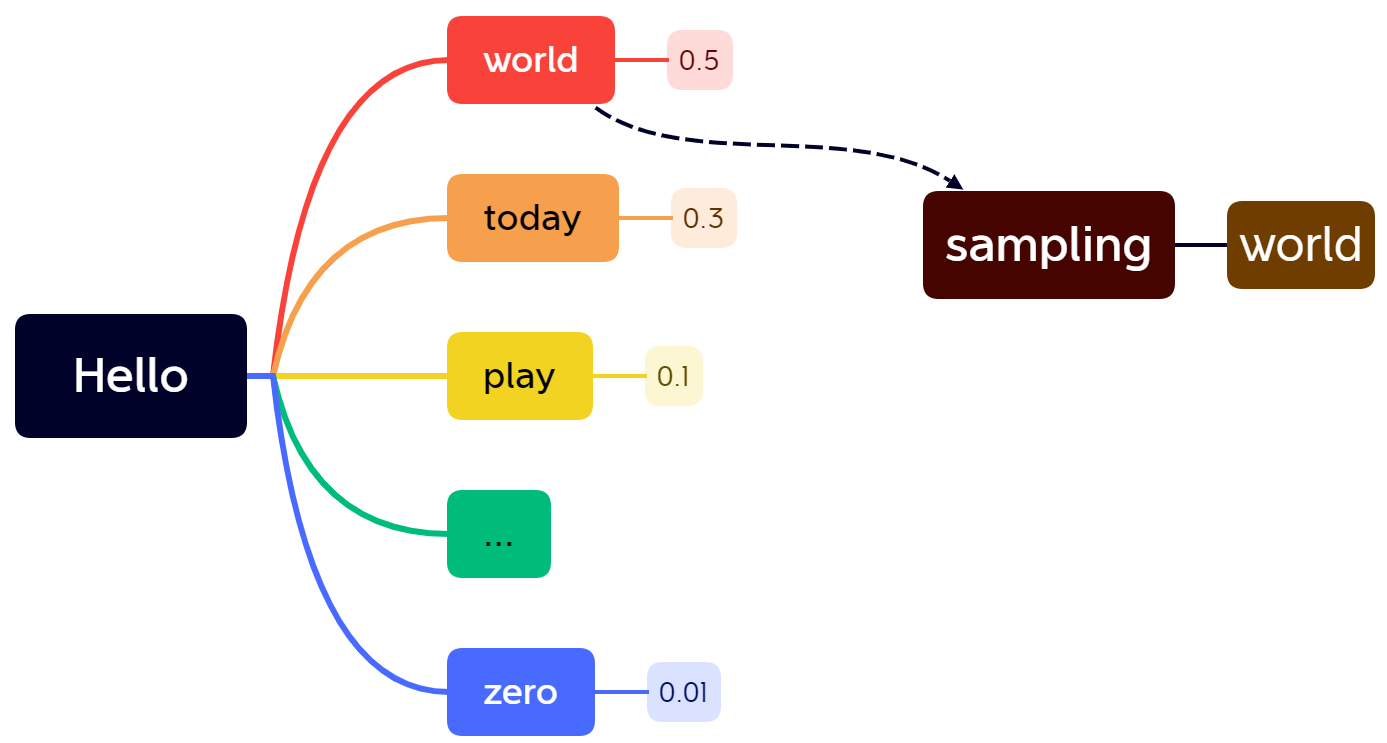
利用自监督训练进行文本生成,在训练中向模型中输入前面的单词,让模型自动预测后面的单词。预测得到的是可能单词的一个概率分布,通过beam search可以采样得到下一个词。然后再将最新生成的词也输入模型中再得到接下来的输出。由于输出结果是随机采样得到的,因此每次输出的结果是随机的。
实际上仅仅通过自监督训练已经可以完成ChatGPT中的问答任务了,例如:世界上最高的山在哪里?,将问题输入到模型中让模型进行文字生成,然后将生成文字作为问题的答案。但是这种模型仍然有很大的缺陷:
- 由于每次的输出是随机采样得到的,因此每次得到的结果都是不固定的。
- 由于训练文本的复杂性往往无法得到可靠的结果
为了解决以上的问题,ChatGPT使用了人工标注的QA数据进行了监督训练
监督QA训练
为了提升网络对问答的准确性,首先收集一部分{“问题”,“答案”}数据,将问题答案数据对输入到模型中进行监督训练以提升模型对问答的可靠性。
值得注意的是,如果有标注数据的规模足够大,那么就可以模型的性能会最够好,但是人工标注的QA数据非常难以收集,而且昂贵。因此ChatGPT的训练中只使用了少量的标注数据,然后同构后续的步骤进一步提升模型的性能。
监督学习人类的喜好
和人工标注的QA文本对相比,如果由人工标注ChatGPT生成答案的优先性更为方便快捷。实际上对ChatGPT来说,它能够生成正确的答案,它只是不知道哪一个答案更好而已。OpenAI雇佣了大量的人工对ChatGPT产生的答案进行评分和排序,然后利用收集到的数据训练一个评价网络
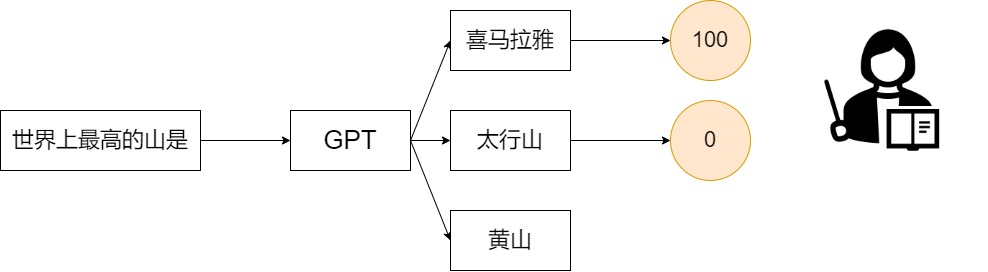 在评价网络中的训练中,将问题和ChatGPT生成的答案同时输入网络中,网络会输出一个分数
在评价网络中的训练中,将问题和ChatGPT生成的答案同时输入网络中,网络会输出一个分数
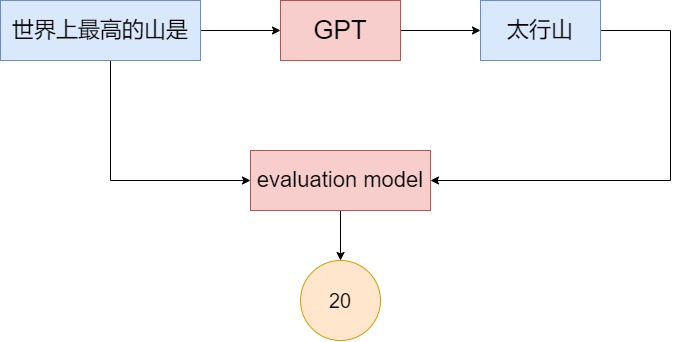 分数越高的答案就意味着答案更符合人类的喜好。
评估模型训练的损失函数可以表示为:
分数越高的答案就意味着答案更符合人类的喜好。
评估模型训练的损失函数可以表示为:
\[ \operatorname{loss}(\theta)=-\frac{1}{\left(\begin{array}{c} K \\ 2 \end{array}\right)} E_{\left(x, y_{w}, y_{l}\right) \sim D}\left[\log \left(\sigma\left(r_{\theta}\left(x, y_{w}\right)-r_{\theta}\left(x, y_{l}\right)\right)\right)\right] \]
式中\(r_{\theta}\)表示训练的评价网络,而\(x\)表示输入ChatGPT中的问题,\(y_w\)和\(y_l\)表示ChatGPT输出的两个不同的答案,其中\(y_w\)为更好的那个答案,因此损失函数实际上就是让网络更能够区分两个不同质量的答案。损失函数前面的组合数实际上表示对同一个问题ChatGPT输出的答案数量,对输出的答案进行优先级排序就能够得到多个组合,可以大幅度提高数据的利用率。
强化学习
强化学习的目标函数为
\[ \begin{aligned} \operatorname{objective}(\phi)= & E_{(x, y) \sim D_{\pi_{\phi}^{\mathrm{RL}}}}\left[r_{\theta}(x, y)-\beta \log \left(\pi_{\phi}^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right)\right]+ \\ & \gamma E_{x \sim D_{\text {prerrain }}}\left[\log \left(\pi_{\phi}^{\mathrm{RL}}(x)\right)\right] \end{aligned} \]
强化学习的目标函数包括三项,首先第一项表示\(r_{\theta}(x, y)\)评价模型,强化学习目标是调整ChatGPT参数,使得评价模型对ChatGPT输出的答案评分最高。
目标函数的第二项实际上是一个KL散度,\(\pi^\mathrm{SFT}\)表示通过人工标注QA数据训练的ChatGPT模型,而\(\pi_{\phi}^{\mathrm{RL}}\)表示强化学习要学习的网络。这一项的意义实际上表示通过强化学习的网路要和通过标注QA学习得到的网络要尽可能接近,不希望网络有太大的改变。这一项是强化学习PPO-ptx 模型的主要创新点。
目标函数的第三项表示ChatGPT预训练中的损失函数,网络训练中不希望通过微调提升了问答任务的表现但是使得预训练中的生成任务性能下降,因此把预训练中损失函数拿过来防止网络在其他任务上的性能下降。
总结
- ChatGPT简单来说就是将GPT3再在标注数据上进行微调。
- ChatGPT对很多问题都能得到很好的结果,但是,它本质上仍然是基于数据的模型,因此如果问ChatGPT一些没有用的问题,ChatGPT就可能出现问题。